Composants internes du processeur
Introduction
Si vous savez utiliser un langage de haut niveau tel que C, BASIC, Python ou Java, vous êtes sans doute familier avec des concepts tels que les instructions If-Then-Else ainsi que les boucles (While, For, etc.) et les fonctions. Vous avez peut-être même une expérience de l’utilisation d’un RTOS (système d’exploitation temps réel) sur un microcontrôleur. Par contre, savez-vous comment ces éléments sont implémentés en interne sur le processeur ? Le CPU est constitué de trois principaux blocs conceptuels :
- Le processeur lui-même, qui exécute le code d’instruction.
- Le code d’instruction à exécuter
- La mémoire de travail (RAM)
Code d'Instruction
Le code d’instruction peut être considéré comme une longue liste d’instructions – une instruction par ligne, chaque ligne ayant un numéro (« adresse »). Le code d’instruction est exprimé dans le langage d’assemblage natif du processeur, qui diffère d’une architecture à l’autre (le même code C produira un code d’assemblage différent, par exemple pour les processeurs x86 et ARM lors de la compilation).
Le Compteur de Programme
Typiquement, le processeur commence au début de la liste des instructions et descend la liste, exécutant une instruction après l’autre. Le processeur possède ce qu’on appelle un Compteur de Programme (PC – program counter, à ne pas confondre avec un ordinateur personnel) qui garde la trace de la ligne de code (adresse) qui est actuellement exécutée. Après l’exécution de l’instruction, le Compteur de Programme (PC) passe automatiquement à la ligne suivante (adresse).
Les instructions peuvent effectuer des actions telles que lire et écrire dans la mémoire, ajouter/soustraire/multiplier des nombres, manipuler des bits dans un octet, etc. Le code d’instruction est généralement stocké dans une mémoire non-volatile telle que FLASH, car il reste généralement inchangé et n’a pas besoin d’être modifié régulièrement. Non-volatile signifie que la mémoire conserve/se souvient de son contenu lorsque l’alimentation est coupée – voir notre article sur la mémoire FLASH pour plus d’informations. Certaines valeurs constantes (par exemple, les octets qui composent un logo bitmap) peuvent également être stockées dans la FLASH. Les valeurs de travail (les valeurs des variables) sont stockées dans la RAM volatile (volatile signifiant que la mémoire perd/oublie son contenu lorsque l’alimentation est coupée).
Conditions et Sauts
Outre l’exécution simple des instructions l’une après l’autre, ligne par ligne, certaines instructions peuvent faire sauter le compteur de programme d’une ligne, ou effectuer un saut complet vers un numéro de ligne spécifique (ou techniquement par un certain décalage). Ces instructions peuvent être utilisées pour implémenter des instructions de type If-Then-Else (conditions), ainsi que des boucles et des fonctions (sauts). Par exemple, une condition très simple, qui allume une LED lorsqu’un bouton est pressé, pourrait être :
1. Test (lecture) un bit en entrée (bouton), sauter une ligne si zéro |
Si le bouton est pressé, aucun saut de ligne ne se produira et la ligne 2 s’exécutera, allumant la LED. Si le bouton n’est pas pressé, la ligne 2 sera sautée et ne s’exécutera pas et la LED ne s’allumera pas.
1. Mettre la Valeur 10 dans notre variable |
Lorsque le code atteint la ligne #3, il décrémentera la variable ; 9, 8, 7, 6, etc. Tant que la variable ne tombe pas à zéro, aucun saut ne se produira après la ligne #3 et la ligne #4 s’exécutera, renvoyant l’exécution à la ligne #2. Une fois la variable à zéro, la ligne #4 sera sautée et l’exécution du code reprendra à partir de la ligne #5.
Avec un peu d’expérience en codage, vous constaterez que certaines sections de code peuvent être réutilisées (au lieu de les copier-coller continuellement), et c’est là que les fonctions interviennent. Par exemple, vous pouvez souhaiter avoir une fonction qui active et désactive une LED un certain nombre de fois. Nous aurions besoin de deux variables – une variable de comptage et une variable de retour. Dans le code ci-dessous, le code en vert représente la fonction, et le code en orange représente les appels de fonction.

Pseudo-code illustrant le besoin fondamental des fonctions.
La Pile
Étant donné que ce type de situation se produit assez fréquemment, et parce que les fonctions peuvent elles-mêmes appeler (sauter vers) d’autres fonctions, les processeurs ont des instructions spécifiques pour gérer ces types de scénarios. Il existe une zone de mémoire appelée pile ainsi que des instructions pour manipuler la pile. Une pile est une zone de mémoire qui est utilisée exactement comme son nom l’indique – c’est comme une pile de papiers où l’on ne peut travailler qu’avec le papier du dessus : soit ajouter un papier au-dessus, soit en retirer un du dessus. Ajouter un papier au sommet est appelé empiler, et retirer un papier du sommet est appelé dépiler.
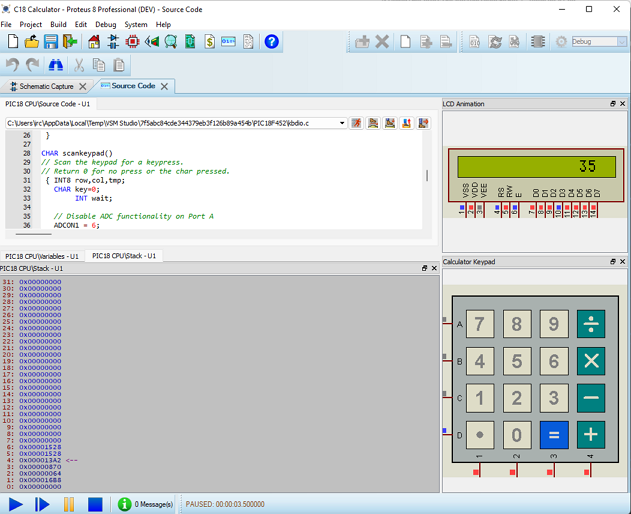
Vous pouvez voir la profondeur de la pile et les appels de fonctions push/pop lorsque vous effectuez un débogage pas à pas d’une simulation Proteus.
Le terme technique relatif à cette utilisation de la mémoire est LIFO (last in first out -dernier entré, premier sortie). Lorsque du code appelle une fonction, il exécute une instruction qui pousse (push) une adresse de retour (line #) dans la pile puis saute à la ligne # de la fonction. L’instruction pousse ajoute la ligne courante (l’adresse du compteur programme), plus un décalage (nous souhaitons revenir à la ligne # après l’exécution de l’instruction d’appel de la fonction), au sommet de la pile. Lorsque la fonction appelée se termine, une instruction de retour vient dépiler la pile pour revenir à la ligne #. Si la fonction doit appeler d’autres fonctions (ou s’appeler elle-même, de manière récursive), les adresses de retour (line #s) sont empilées dans la pile pour y être retirées ensuite. Si trop de fonctions sont appelées en séquence et que la pile n’est pas assez grande pour contenir toutes les adresses, on aboutit à un dépassement de capacité appelé « stack overflow ».
Un niveau de complexité supplémentaire intervient pour passer des paramètres à une fonction et récupérer les valeurs de retour en sortie de fonction ; dans tous les cas, c’est toujours le concept de pile qui est utilisé.
RTOS
Un système d’exploitation temps réel, ou RTOS, permet d’exécuter plusieurs « tâches » en parallèle, en maintenant une copie de la pile et du compteur de programme pour chaque tâche, et en passant de l’une à l’autre.
Interruptions
Pour terminer, voyons le concept d’interruptions. Une interruption est une fonctionnalité du processeur où, lors d’un événement externe (par exemple, une broche d’entrée passe à l’état haut), le processeur sauvegarde automatiquement l’état actuel (compteur de programme, etc.) dans la pile et sautera l’exécution vers une routine d’interruption spéciale (fonction). Lorsque la routine d’interruption a terminé son exécution, elle dépile à nouveau et l’opération normale du programme reprend.
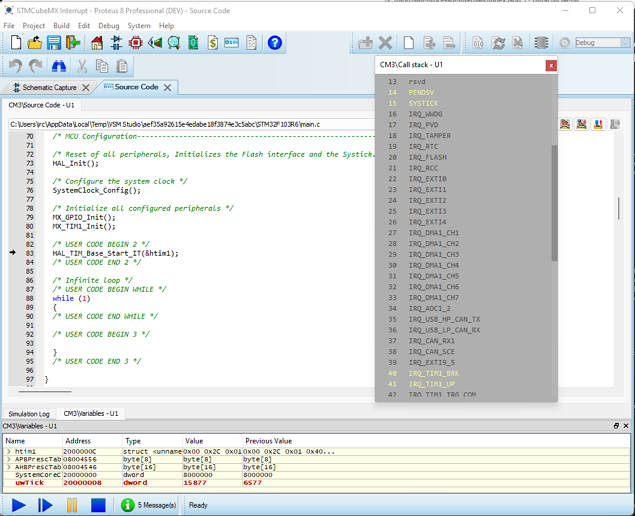
Les microcontrôleurs modernes disposent d’un vaste éventail de sources d’interruptions et de priorités (Cortex-M3 illustré ci-dessus).
Conclusion
La manière dont les processeurs mettent en œuvre les piles et les interruptions est beaucoup plus subtile, mais ils utilisent tous les concepts de base décrits dans cet article. Les compilateurs masquent la complexité de tous ces détails, cependant, avoir une compréhension pratique de ce qui se passe sous le capot peut aider à déboguer et valider des projets avancés.
Copyright Labcenter Electronics Ltd. 2024
Traduction française
Copyright Multipower France 2024